

- 617.50 KB
- 2022-04-29 14:28:52 发布

- 1、本文档共5页,可阅读全部内容。
- 2、本文档内容版权归属内容提供方,所产生的收益全部归内容提供方所有。如果您对本文有版权争议,可选择认领,认领后既往收益都归您。
- 3、本文档由用户上传,本站不保证质量和数量令人满意,可能有诸多瑕疵,付费之前,请仔细先通过免费阅读内容等途径辨别内容交易风险。如存在严重挂羊头卖狗肉之情形,可联系本站下载客服投诉处理。
- 文档侵权举报电话:19940600175。
'角平分线的性质与判定的习题
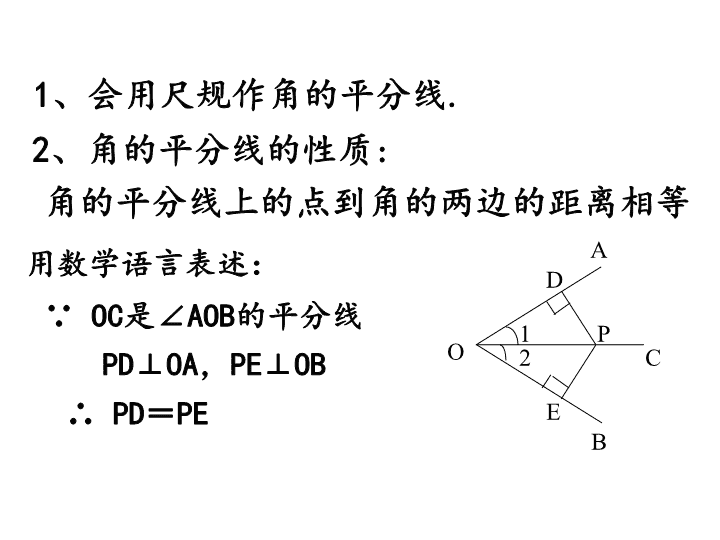
1、会用尺规作角的平分线.角的平分线上的点到角的两边的距离相等2、角的平分线的性质:OCB1A2PDEPD⊥OA,PE⊥OB∵OC是∠AOB的平分线∴PD=PE用数学语言表述:
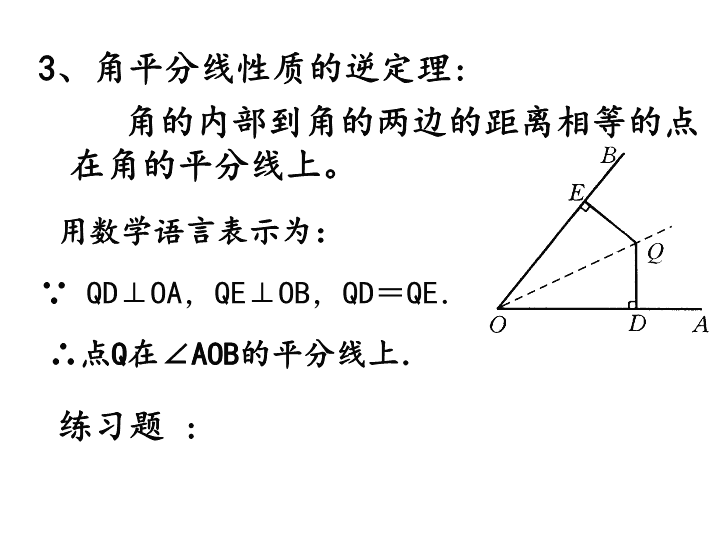
角的内部到角的两边的距离相等的点在角的平分线上。∵QD⊥OA,QE⊥OB,QD=QE.用数学语言表示为:3、角平分线性质的逆定理:∴点Q在∠AOB的平分线上.练习题:
5.如图,OP平分∠MON,PA⊥ON于点A,点Q是射线OM上的一个动点,若PA=2,则PQ的最小值为( )A.1B.2C.3D.4B
6.如图所示,在△ABC中,∠C=90°,AD平分∠BAC,AE=AC,下列结论中错误的是( )A.DC=DE B.∠AED=90°C.∠ADE=∠ADC D.DB=DCD
7.如图所示,△ABC中,∠C=90°,AC=BC,AD平分∠CAB交BC于D,DE⊥AB于E,且AB=6cm,则△DEB的周长为( )A.4cm B.6cmC.10cm D.以上都不对B
8.如图在△ABC中,∠ACB=90°,BE平分∠ABC,DE⊥AB于D,如果AC=3cm,那么AE+DE等于()A.2cmB.3cmC.4cmD.5cmB
9.如图,在△ABC中,∠C=90°,AD是角平分线,DE⊥AB于E,且DE=3cm,BD=5cm,则BC=_____cm.8
10.如图,∠AOB=60°,CD⊥OA于D,CE⊥OB于E,且CD=CE,则∠DOC=____.30°
A0BMNPC11.如图,OC平分∠AOB,PM⊥OB于点M,PN⊥OA于点N,△POM的面积为6,OM=6,则PN=_______。2
12.已知:如图,在Rt△ABC中,∠C=90°,D是AC上一点,DE⊥AB于E,且DE=DC.(1)求证:BD平分∠ABC;(2)若∠A=36°,求∠DBC的度数.或:证△BDE≌△BDC(HL).(1)根据角平分线性质的逆定理:(2)∠DBC=27°
13.如图,∠1=∠2,AE⊥OB于E,BD⊥OA于D,AE与BD相交于点C.求证:AC=BC.
14.如图,∠B=∠C=90°,M是BC的中点,DM平分∠ADC,求证:AM平分∠DAB.
15.如图:在△ABC中,∠C=90°,AD是∠BAC的平分线,DE⊥AB于E,F在AC上,BD=DF;求证:CF=EBACDEBF
16.如图,AB=AC,BD=CD,DE⊥AB于E,DF⊥AC于F,求证:DE=DFAFEDCB
17.如图,在∠BAC的平分线上任取一点D,在AB,AC上各取一点E,F,若DE=DF,且AE>AF求证:∠AED=∠DFCAFEDCBMN
18.如图,已知△ABC的周长为10,OB、OC分别平分∠ABC、∠ACB、OD⊥BC于点D,且OD=2,求△ABC的面积。ABCOD
19.如图Rt△ABC中,∠C=90。AC=BC,AD是∠BAC的平分线,DE⊥AB于E,求证:△DBE的周长等于AB长BCADE
决策树方法在数据挖掘中的应用1KnowledgeSEEKER简介2数据准备3定义研究对象4建立模型5理解模型6预测
1KnowledgeSEEKER简介KnowledgeSEEKER是一个由Angoss公司开发的基于决策树的数据分析程序。该程序具有相当完整的分类树分析功能。KnowledgeSEEKER采用了两种著名的决策树分析算法:CHAID和CART算法。CHAID算法可以用来对于分类性数据进行挖掘。CART算法则可以对连续型因变量进行处理。Angoss公司在增强这些算法的用户友好性方面作了大量的工作。优点:响应快,模型,文档易于理解,决策树分析直观,性能良好缺点:决策树不能编辑打印,缺乏数据预处理阶段的函数,没有示例代码
1KnowledgeSEEKER简介应用行业案例:FrostNational银行CRM收益率、客户满意度、产品功效SASI公司利用其开发行业数据挖掘应用软件(零售行业)Montreal银行客户分片、越区销售模型、市场站的准备、抵押支付的预测、信用风险的分析
2数据准备使用的样例数据集是从一个团体健康检查中有关高血压的研究项目中得到的。Angoss公司已将这一数据集包括在产品演示中。有关高血压研究方面的数据(表中给出数据集中各个数据列的取值范围及其含义说明)
2数据准备数据预处理:1)对数据域中所含的整数值进行标注:Hypertension(高血压)域中可以出现整数值1,2,3,这几个值将分别被标注为低,正常,高。TypeOfMilk域中包含整数值1~5,将分别标注为纯牛奶、2%,脱脂牛奶,奶粉及根本不喝牛奶2)处理导出型的数据域字段Age中包含的值1,2,3分别表示32~50岁、51~62岁及63~73岁。然而,字段Age中通常包含的都是某个人的实际年龄而非整数值1,2,3,因此,字段Age中的值是在数据挖掘开始之前就已经导出了,即按照实际年龄的范围32~50岁、51~62岁及63~73岁对该字段选择适当的值。
3定义研究对象1、定义挖掘目标在开始使用KnowledgeSEEKER之前,有必要定义出挖掘的目标。在给定的数据集的例子中展示了哪些饮食因素会对人的血压高低有关键性的影响。其挖掘的目标可以明确地描述为:分析出饮食因素对血压偏低、正常及偏高所产生的影响。
3定义研究对象2、启动
3定义研究对象3、设置因变量一开始,字段Hypertension就已经被自动设置为因变量。稍后,还将改变因变量的设置。打开bpress数据集之后将出现如图所示的屏幕。
3定义研究对象图中的根结点对应的是因变量。在根节点中血压已经分别被分为3类:偏低、正常和偏高。我们现在要了解的是血压偏低、正常和偏高的人都分别具有哪些特征。从图中可以看出:研究对象中有18%的人(即66个人)血压偏低研究对象中有60%的人(即217个人)血压正常研究对象中有21%的人(即77个人)血压偏高
4建立模型目前KnowledgeSEEKER已经构造出模型树的下一层分支。当然,模型树还可以自动生成出多层分支。图中的模型树的下一层分支表明上一层的双亲节点是按年龄(age)进行分叉的。年龄只是影响血压的一个变量,但是在目前这个例子中,年龄似乎是导致一个人的血压是否偏高的最重要因素。如图所示,研究对象按年龄分为以下3组:32~50岁,51~62岁,63~73岁它们分别对应于模型树的三个叶节点。此外,还可以用除Age以外的其他字段为模型树创建新的叶节点。在模型树上通过指定其它字段以创建新的叶节点称为分叉。对于当前这个数据集,系统会自动发现12个分叉。
5理解模型1)观察其分叉观察其分叉将使我们可以看到除年龄以外对血压还有影响的其他重要变量的作用。KnowledgeSEEKER可以计算出所有变量对血压影响的大小并将使它们按顺序排列起来。用另一个变量直接在根节点下面构造叶节点即可进入模型树的另一个分叉。这样,我们就可以很容易地观察到其他数据元素对血压的影响。对于自动生成的每一个分叉所作的概述将为我们考虑下一步的研究方向提供有益的线索。很明显,所获得的信息中有一些符合我们的预先估计;然而,我们从数据集中也发现了一些预先没有估计到的结果,如人的身高与其高血压之间的关系就是我们预先没有估计到的。
5理解模型2)进入特定分叉3)扩展模型树以smoking为分叉变量构造的模型树目前还只有一层。我们可以对这棵模型树作进一步扩展。在模型树的第二层中选择经常吸烟者相对应的节点,然后,在Grow下拉菜单中选择FindSplit,即可以看到如图所示的屏幕。
5理解模型KnowledgeSEEKER发现对于描述经常吸烟者特征最为有效的分组变量就是年龄。也就是说,对于经常吸烟的人而言,年龄将是确定其是否患高血压的最关键的指标,数据表明年龄在63~73岁之间经常吸烟的人当中有56.7%患有高血压,而年龄在32~51岁之间且经常吸烟的人当中患有高血压的比例仅为4.8%。为进一步描述经常吸烟者的特征,KnowledgeSEEKER总共发现了6个分叉变量,分别是Age,Height,PorkLastWeek,DrinkPattern,Gender以及SaltConsumption。其中以年龄最为有效。
5理解模型4)强制分叉有时我们还想观察一下那些没有自动发现的变量的作用。例如,我们可能想知道PoultryLastWeek对人们患有高血压有什么影响。为此,我们可以在模型树上作强制分叉。
5理解模型5)对模型进行验证当我们从一个数据集中发现某些结果之后,总是希望能够用另外一个数据集再对其进行验证。Angoss将那些用于验证的数据集又称为测试分区(TestPartition)。KnowledgeSEEKER允许我们用另一个数据集(即测试分区)对新发现的结果进行验证。
5理解模型6)重新定义挖掘对象假如我们想要改变所研究的内容(例如,想要研究饮酒数量不同的人之间的差别),那么就需要重新定义研究对象。改变模型树的根节点为DrinkPattern,即新的模型树的根节点对应的因变量为DrinkPattern,其中可以含有下列值:Regular(经常饮酒)Occasional(偶然饮酒)Former(以前曾经饮酒)Never(从不饮酒)可以对这棵以DrinkPattern为因变量的模型树作进一步的扩展。虽然这期间使用KnowledgeSEEKER的工作方式与前面是一样的,但所要研究的内容与前面完全不同了,即现在要研究的是人们的饮酒方式及其影响。
5理解模型7)模型树的自动扩展前面所演示的都是如何一个一个节点地扩展模型树。此外,还可以让系统对模型树作自动扩展。8)数据分布KnowledgeSEEKER提供了若干种方法以便我们能够对正在挖掘的数据的状态进行观察。首先,我们能够通过KnowledgeSEEKER对正在挖掘的原始数据进行详细观察。另外,还可以通过KnowledgeSEEKER对数据几种不同数据项的交叉列表视图进行观察。
6预测现在我们已经有了一个可以用来作预测的模型。虽然用决策树来做决策不是一个可以自动进行的过程,但KnowledgeSEEKER允许我们将所有变量的分叉保存在外部文件中。此外,我们还可以用百分比的形式计算出每一个分叉的重要性。使用上述信息,将使我们有可能产生出有助于预测的规则。'
您可能关注的文档
- 最新视力与口腔保健剧场课件PPT.ppt
- 最新视力保健宣导【精品-】课件PPT.ppt
- 最新视网膜病 07_林学_农林牧渔_专业资料课件PPT.ppt
- 最新视网膜色素变性并发性白内障12 课件PPT课件.ppt
- 最新视觉障碍解剖及定位诊断课件PPT.ppt
- 最新视觉障碍儿童_PPT课件PPT课件.ppt
- 最新视觉障碍和眼球运动障碍课件PPT课件.ppt
- 最新视觉障碍43课件PPT.ppt
- 最新视觉里程计原理(二)特征匹配与追踪(LK光流法)课件PPT.ppt
- 最新角膜病课件PPT.ppt
- 最新角膜病2 课件PPT课件.ppt
- 最新解三角形单元复习-----(3课时)课件PPT.ppt
- 最新解一元一次方程(移项)ppt课件---修改课件PPT.ppt
- 最新解决问题(例5)(3)课件PPT.ppt
- 最新解三角形课件高三复习课课件PPT.ppt
- 最新解剖学【纵隔淋巴结断层解剖】课件PPT.ppt
- 最新解方程例4、例5PPt课件PPT.ppt
- 最新解剖生理课件--呼吸系统(非常好)课件PPT.ppt