

- 3.01 MB
- 2022-04-29 14:39:33 发布


- 1、本文档共5页,可阅读全部内容。
- 2、本文档内容版权归属内容提供方,所产生的收益全部归内容提供方所有。如果您对本文有版权争议,可选择认领,认领后既往收益都归您。
- 3、本文档由用户上传,本站不保证质量和数量令人满意,可能有诸多瑕疵,付费之前,请仔细先通过免费阅读内容等途径辨别内容交易风险。如存在严重挂羊头卖狗肉之情形,可联系本站下载客服投诉处理。
- 文档侵权举报电话:19940600175。
'《图形的运动(三)》课件1
顺时针旋转逆时针旋转
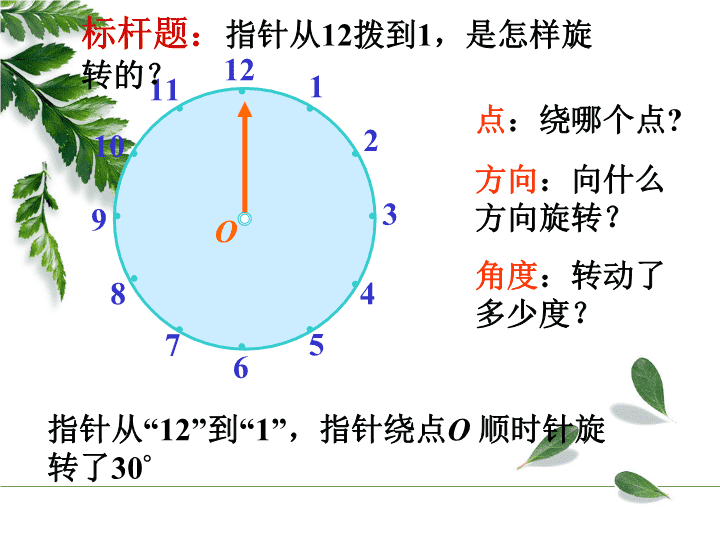
指针从“12”到“1”,指针绕点O顺时针旋转了30°121234567891011O标杆题:指针从12拨到1,是怎样旋转的?点:绕哪个点?方向:向什么方向旋转?角度:转动了多少度?
小结2、旋转一般从旋转中心、旋转方向、旋转角度三个方面去描述图形是如何旋转的。1、旋转是物体绕某一个点或轴运动。
左侧有车通过,车杆要绕点按顺时针方向旋转90°右侧有车通过,车杆要绕点按方向旋转。逆时针90°类比题
1.下面的图案分别是由哪个图形旋转而成?强化训练
钟摆绕点O(顺)时针旋转不超过10°。钟摆绕点O(逆)时针旋转不超过10°。2.
风车绕点O(逆)时针旋转90°。风车绕点O(逆)时针旋转90°。3.
(1)图形OABC绕点O顺时针旋转90°,在右图中标出点A的对应点A′。(2)图形OABC绕点O()时针旋转(),得到图2。
如图,长方形的两条对称轴相交于点O,绕点O旋转长方形,你能发现什么?拓展:
利用平移、对称和旋转,可以设计出许多美丽的图案欣赏
第八章聚类分析8.1聚类分析的步骤8.2相似性测度8.3聚类方法8.4聚类结果的解释8.5利用SPSS进行聚类分析
聚类分析(ClusterAnalysis)是根据研究对象的特征对研究对象进行分类的多元统计分析技术。它的基本思想是,认为我们所研究的案例(cases)或指标(variables)之间存在着程度不同的相似性(亲疏关系)。首先找出一些能够度量案例或指标之间相似程度的统计量,以此为划分类别的依据,然后,把一些彼此之间相似程度较大的聚合为一类,把另外一些彼此之间相似程度较大的聚合为另一类,关系密切的聚合到一个相对较小的分类单位,关系疏远的的聚合到一个相对较大的分类单位,直到把所有的都聚合完毕,把不同类型一一划出来,形成由小到大的分类系统。最后,再把整个分类系统画成一张谱系图,用它把所有案例(或指标)间的亲疏关系表示出来。
聚类分析的大部分应用都属于探索性研究,最终的结果是产生研究对象的分类,通过对数据分类的研究提出假设;聚类分析还可以用于证实(或验证)性目的,对于通过其他方法确定的数据分类,可以应用聚类分析进行检验。聚类分析根据分类对象的不同,分为Q型聚类和R型聚类。对案例的分类称为Q型聚类,对变量的分类称为R型聚类。
R型聚类分析的作用1、不但可以了解个别变量之间的亲疏程度,而且可以了解各变量组合之间之间的亲疏程度;2、根据变量的聚类结果以及它们之间的关系,可以选择主要变量进行回归分析或Q型聚类分析。选择主要变量的方法是:在聚合的每类变量中各选出一个有代表性的变量作为典型变量。计算每一个变量与同类其他变量的样本决定系数R2,挑选其最大者作为该类的典型变量。
Q型聚类分析的作用与优点1、可以综合利用多个变量的信息对样本进行分类;2、分类结果是直观的,聚类谱系图非常清楚地表现案例的分类结果;3、聚类分析所得到的结果比传统分类方法更细致、全面、合理。本章主要介绍Q型聚类。
8.1聚类分析的主要步骤1、选择聚类分析变量这些变量应具备以下特点:(1)和聚类分析的目标相关;(2)反映了要分类对象的特征;(3)在不同对象的值具有明显差异;(4)变量之间不应该高度相关。
对于变量高度相关的处理办法(两种):1)在对案例聚类分析之前,先对变量进行聚类分析,在各类中选择具有代表性的变量作为聚类变量;2)对变量做因素分析,产生一组不相关变量作为聚类变量。
2、计算相似性相似性(Similarity)是聚类分析的一个基本概念,反映了研究对象之间的亲疏程度。聚类分析就是根据研究对象之间的相似性来进行分类的。3、聚类选定聚类方法,确定形成的类数。4、聚类结果的解释得到聚类结果后,对结果进行验证和解释,以保证聚类解是可信的。
8.2相似性测度8.2.1相似系数8.2.2距离测度8.2.3关联测度
8.2.1相似系数
8.2.2距离测度每个样品(案例)有p个指标(变量),故每个样品可以看成p维空间中的一个点,n个样品组成p维空间中的n个点,用距离来度量样品之间接近的程度。距离测度应满足下列四个条件:1)dij0;2)dij=dji,即距离具有对称性;3)dijdik+dkj,即三角不等式,任意一边小于其他两边之和;4)如果dij0,则ij
常见的几种距离:
*:当各指标的测量值相差悬殊时,先对数据标准化,然后,用标准化后的数据计算距离。
8.2.3关联测度关联测度用来度量聚类变量为分类变量的研究对象的相似性。1、简单匹配系数(Simplematchingcoefficient)适用于二分变量。估计研究对象在回答这些问题时的一致性程度。案例210案例11ab0cd
2、雅可比系数(Jaccard’scoefficient)雅可比系数在简单匹配系数的基础上做了一些改进,它把两个案例都回答“否”的部分从公式中去掉,只考虑“是”的部分。
3、果瓦系数(Gower’scoefficient)果瓦系数优于前两个关联测度之处在于它允许聚类变量可以是名义变量、顺序变量和等距变量。定义为:
8.3聚类方法8.3.1层次聚类法(HierarchicalClusterProcedures)聚集法(AgglomerativeMethod)分解法(DivisiveMethod)8.3.2迭代聚类法(IterativePartitioningProcedures)
8.3.1层次聚类法1、聚集法:首先把每个案例各自看成一类,先把距离最近的两类合并,然后重新计算类与类之间的距离,再把距离最近的两类合并,每一步减少一类,这个过程一直持续到所有案例归为一类为止。2、分解法:与聚集法相反,首先把所有的案例看成一类,然后把最不相似的案例分为两类,每一步增加一类,直到每个案例都成为一类为止。
3、层次聚类中计算类与类之间的距离(1)最短距离法(SingleLinkage)类与类之间的距离定义为一个类中的所有案例与另一类中的所有案例之间的距离最小者。(2)最长距离法(CompleteLinkage)与最短距离法相反,类与类之间的距离定义为两类中离得最远的两个案例之间的距离。
(3)平均联结法(AverageLinkage)两类之间的距离定义为两类中所有案例之间距离的平均值,分为:组间联结法(Between-groupslinkage)和组内联结法(Within-groupslinkage)。(4)重心法(Centroid)两类之间的距离定义为两类重心之间的距离。每一类的重心是该类中所有案例在各个变量上的均值所代表的点。(5)离差平方和法(Ward’sMethod)该方法的基本思想是同一类案例的离差平方和尽量较小,不同类之间案例的离差平方和尽量较大。求解过程是首先使每个案例自成一类,每一步使离差平方和增加最小的两类合并为一类,直到所有的案例都归为一类为止。以上几种方法,离差平方和法和平均联结法的分类效果较好。
主要结果聚合进度表冰柱图(垂直、水平)树状图案例归类表
聚类进度表
垂直冰柱图
case4clusters3clusters2clusters123456789101112131415121223333344444111112222233333111111111122222案例归类表
8.3.2迭代聚类法迭代聚类法也称快速聚类法,具有占计算机内存小、速度快的优点,适用于大样本的聚类分析。该方法有四个步骤:(1)指定要形成的聚类数,对样本进行初始分类并计算每一类的重心;(2)调整分类。计算每个样本点到各类重心的距离,把每个样本点归入距重心最近的那一类。(3)重新计算每一类的重心;(4)重复(2)-(3),直到没有样本点可以调整为止。
分类数的确定方法1、根据树状图确定分类数的准则:(1)各类重心之间距离必须较大;(2)各类所包含的元素都不要过多;(3)分类的数目应符合使用的目的;(4)若采用几种不同的聚类方法,则在各自的聚类图上应发现相同的类。方法2、根据聚合系数的变化确定分类数
8.4聚类结果的解释所谓聚类结果的解释是指对各个类的特征进行准确的描述,给每类一个合适的名称。可以计算各类在各聚类变量上的均值,对其进行比较,还可以使用聚类变量以外的变量,帮助描述各个类的特征,解释各个类差别的原因。
迭代聚类结果的各类样本的均值和显著性差异类变量类别123有显著差异类经济生活指数教育生活指数健康生活指数居住生活指数0.38350.78430.95320.55000.21360.41300.82930.85120.09910.22450.15440.6223(1,2)(1,3)(2,3)(1,2)(1,3)(2,3)(1,3)(2,3)(1,2)(2,3)将30各省份分成了三类:一类地区:经济、教育和健康方面皆高于其他地区;二类地区:居住方面标准最高,健康指数较高;三类地区:居住方面较高,其他方面低于一、二类。
8.5利用SPSS进行聚类分析层次聚类法(菜单选择)Analyzeclassifyhierarchicalclustervariable(指定聚类变量)cluster(指定聚类对象)cases(对案例聚类)variables(对变量聚类)method(指定聚类方法、相似测度方法和标准化数据的方法)clustermethod(聚类方法)measure(相似测度)intervalbinarycountsstatisticsagglomerationschedule(聚合进度表)proximitymatrix(相似矩阵)clustermembership(聚类结果)plots(树状结构图、冰柱图)dendrogram(树状图)icicle(冰柱图)save(数据文件中以变量形式保存聚类结果)singlesolutionrangeofsolution
层次聚类法命令文件PROXIMITIESeconomyeducatiohealthhouse/MATRIXOUT("C:WINDOWSTEMPspss4294687875spssclus.tmp")/VIEW=CASE/MEASURE=SEUCLID/PRINTNONE/STANDARDIZE=VARIABLEZ.CLUSTER/MATRIXIN("C:WINDOWSTEMPspss4294687875spssclus.tmp")/METHODBAVERAGE/PRINTSCHEDULECLUSTER(3,6)/PRINTDISTANCE/PLOTDENDROGRAMVICICLE/SAVECLUSTER(3,6).ERASEFILE="C:WINDOWSTEMPspss4294687875spssclus.tmp".
迭代聚类法(菜单选择)Analyzeclassifyk-meansclustervariables(选择聚类变量)numberofcluster(指定聚类数目)centers(指定初始中心)methoditerateandclassifyonlyclassifyiteratemaximumiteration(确定最大迭代次数)convergencecriterion(收敛标准)saveclustermembership(将聚类结果存为新变量)distancefromclustercenter(将每个案例距所属类中心的距离作为新变量存入数据文件)options(选择输出结果)initialclustercenters(初始类中心)anovatable(方差分析表)clusterinformationforeachcase(每个案例的分类信息)
QUICKCLUSTEReconomyeducatiohealthhouse/MISSING=LISTWISE/CRITERIA=CLUSTER(3)MXITER(10)CONVERGE(0)/METHOD=KMEANS(NOUPDATE)/SAVECLUSTERDISTANCE/PRINTINITIALANOVACLUSTERDISTAN.迭代聚类法命令文件:
本章结束!'
您可能关注的文档
- 最新《咏柳》PPT课件课件PPT.ppt
- 最新《唱山歌》音乐课件PPT课件.ppt
- 最新《四大区域自然环境对生产和生活的影响》ppt课件PPT课件.ppt
- 最新《图形的放大与缩小》课件PPT教学讲义PPT.ppt
- 最新《图像处理教学课件》第9章数字形态学及其应用课件PPT.ppt
- 最新《图像重建》PPT课件课件PPT.ppt
- 最新《圆的周长》PPT课件PPT.ppt
- 最新《圆柱的认识》课件PPT幻灯片.ppt
- 最新《圆周角》参考课件PPT课件.ppt
- 最新《图形拼接》课件PPT课件.ppt
- 最新《土地的誓言》优秀课件(推荐)(1)课件PPT.ppt
- 最新《土地利用与规划》期末答疑课件PPT.ppt
- 最新《地球上的红飘带》课件PPT.ppt
- 最新《在烈日和暴雨下》课件课件PPT.ppt
- 最新《墨梅图题诗》艳清课件PPT.ppt
- 最新《墨梅图题诗》PPT课件PPT.ppt
- 最新《塞翁失马》课件课件PPT.ppt
- 最新《外国小说欣赏》话题之二:场景课件PPT.ppt